Un changement d''architecture sans heurt : notre passage à AWS Fargate
Au cours de l’année 2018, nous avons fait le plus grand changement d’architecture de l’histoire de Deepki à ce jour, et tout s’est admirablement bien déroulé, sans heurt, sans souffrance en moins de deux semaines de travail. Nous allons voir dans cet article quel changement nous avons réalisé, pourquoi et comment nous l’avons fait et surtout regarder pourquoi tout cela a été indolore pour nous ; il peut y avoir des conseils et des enseignements à retirer de notre expérience.
NB: cet article est une re-transcription en version longue et détaillée de mon intervention à l’événement AWS Startup Day 2018.
Notre stack applicative chez Deepki
La stack des applications chez Deepki est très classique, elle est la même pour toutes nos applications :
- des serveurs frontaux qui répondent au traffic HTTP(s) et exposent leur API et/ou une IHM pour les utilisateurs ; un serveur de répartition de charge, ou load balancer, est responsable de router le trafic et de répartir la charge entre les serveurs frontaux
- des serveurs “backoffice” qui traitent les tâches en arrière plan : les workers
- un cluster de données
- un bus applicatif pour faire transiter les informations entre les serveurs frontaux et les serveurs backoffice
- un serveur de cache pour les sessions utilisateurs ou pour accélérer les affichages
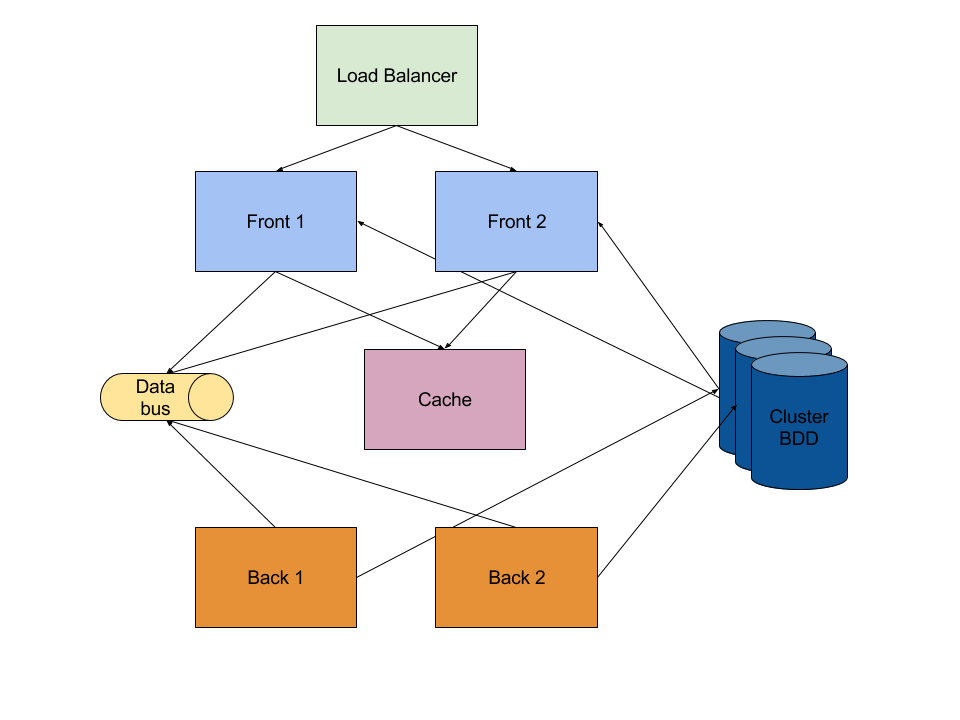
Notre architecture technique (vision d’artiste)
Ce qui va nous intéresser ici, c’est la communication entre les frontaux et les workers. Les workers sont responsables de réaliser tous les traitements coûteux (en temps de calcul et en durée) que les frontaux ne peuvent réaliser. Ils sont également responsables de tous les traitements en mode batch. Les serveurs frontaux et workers communiquent de manière asynchrone via le bus de données ; ils ne communiquent jamais directement entre eux.
Vous l’avez sûrement reconnu ! Il s’agit en effet du pattern très classique Producteur / Consommateur, avec les frontaux qui produisent des tâches à réaliser par les workers qui les consomment. Les workers ont ici pour objectif de libérer le maximum de ressources aux serveurs frontaux pour pouvoir servir toutes les requêtes HTTP qui leur seront demandées.
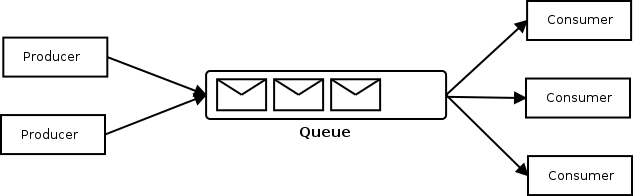
Le pattern Producteur/Consommateur
Enfin, tous ces serveurs sont hébergés chez Amazon Web Services (AWS, l’inventeur du Cloud Computing), ce sont des instances “à la demande” EC2 (Elastic Cloud Compute) : les serveurs virtuels facturés à la minute de AWS. Ces instances fonctionnent 24h/24, 7 jours/7 et en particulier les workers, même quand il n’y a rien à faire pour eux. Nous avons donc des serveurs payés à ne rien faire alors que le Cloud promet de gérer ses ressources de manière élastique (le E de EC2) pour pouvoir réduire ses coûts et de réagir rapidement à une soudaine montée en charge de vos services.
Deepki est une petite entreprise, nous faisons très attention à nos coûts, nous avons vu ici une opportunité de les réduire, mais pas seulement…
Les problèmes que nous rencontrions
Dans cette optique de maîtrise de nos coûts, nous avions fait le choix d’héberger plusieurs de nos applications sur les mêmes serveurs. Ainsi, nous avons encore aujourd’hui principalement 2 plateformes : Deepki Ready (l’application utilisée par nos clients) et “tout le reste” , en particulier les applications de collecte automatisée des données pour nos clients (pour être tout à fait précis, il faut multiplier cela par les environnements de test, de recette, de production).
Plusieurs services sur les mêmes serveurs, cela nous coûte moins cher, mais à quel prix ? Avec la hausse de notre activité, ces serveurs sont de plus en plus sollicités, il y a de plus en plus de travail à accomplir et de nouveaux problèmes émergent :
- Une instabilité croissante : sur un serveur, les workers se battent pour les ressources machines (CPU, RAM) et se canibalisent mutuellement de manière non prédictible : on commençait à entendre très souvent “Mais qu’est-ce qui s’est passé ? Ma tâche XXX a disparu !” ; en effet, si un nouveau process qui demande plus de ressources se lance, il peut tuer un autre (et se faire ensuite tuer par une troisième), ou mourir faute de RAM disponible car un autre process a besoin d’une grande quantité de RAM par exemple
- Interruption des workers au déploiement : à chaque déploiement d’une application (et cela arrive plusieurs fois par jour chez Deepki), les workers en cours de traitement sont arrêtés brutalement, interrompant et jetant à la poubelle potentiellement plusieurs heures de travail. Nous avons passé pas mal de temps à travailler sur nos déploiements pour résoudre cela, mais au final, cela ressemblait plus à des contournements parfois hasardeux et aucun n’a jamais vraiment fonctionné
- Un dimensionnement « par le haut » : comme nous l’avons vu plus haut, dans les périodes d’inactivité, les serveurs restent tout de même branchés, en attente de travail à réaliser : c’est vraiment dommage de gaspiller les ressources de l’entreprise parce que nous ne sommes pas capable de faire mieux ! Il doit bien exister un moyen de rendre notre plateforme plus “élastique” !
- Un sous-dimensionnement pour certaines tâches : le pire de cette histoire, c’est que certaines tâches sont tellement nombreuses et longues à réaliser que nos 3 serveurs de production n’arrivent pas à suivre la cadence que nous désirons pour aller chercher toutes les données dont nous avons besoin (le téléchargement et l’anaylse des factures énergétiques de nos clients). Cela peut sembler contradictoire avec le point précédent n’est-ce pas ? Eh bien on n’est jamais totalement rationnel dans nos choix, nos analyses, on refuse parfois de voir certains problèmes au nom de principes d’architecture inadaptés à la situation : c’est beaucoup plus facile de voir les problèmes une fois qu’ils sont résolus et qu’on a changé de point de vue, qu’on a évolué.
Pour résumer, cela générait beaucoup de frustrations, d’incompréhensions des utilisateurs et il devenait difficile de garantir un produit de qualité, rapide et efficace à coût maîtrisé.
Une alternative aurait été de séparer ces applications sur des plateformes différentes, mais non seulement cela ne résolvait pas tous les problèmes (en particulier ceux liés aux déploiements), mais cela aurait fait bondir nos coûts de façon déraisonnable et nécessité une grande charge de travail dans nos équipes pour migrer ces services sur des plateformes individuelles. Nous avons préféré opter pour l’abandon des serveurs dédiés pour l’hébergement des workers et la création dynamique des instances de travail selon la charge demandée.
Quelques pré-requis
Tout d’abord, cela fait plusieurs années que toute notre production est entièrement automatisée : non seulement la création des plateformes, mais aussi tous nos déploiements applicatifs. Pour cela, nous utilisons le couple terraform + ansible.

Le couple Terraform + Ansible
- Terraform : pour simplifier, terraform remplace tous les clicks que vous pouvez faire dans l’interface d’administration de AWS (ou d’un autre Cloud Provider) par du code : infrastructure as code. C’est avec terraform que nous créons nos serveurs, les réseaux privés, les enregistrements DNS, les droits des utilisateurs…
- Ansible : nous sert à mettre à jour chaque serveur (installation des packages système, mises à jour de sécurité) et à déployer nos applicatifs sur ces serveurs

Docker, l’outil de gestion de conteneurs très à la mode
Par ailleurs, nous avions déjà travaillé avec Docker et AWS ECR (Elastic Container Registry), un registre privé de conteneurs Docker opéré par AWS. Jusqu’à présent, docker nous servait principalement pour les usages suivants :
- sur nos machines locales pour travailler avec exactement les mêmes bases de données qu’en production, sans se casser la tete à installer la “bonne version qui va bien”
- pour réaliser des tests unitaires dans un environnement qui imite à la perfection l’environnement AWS Lambda depuis nos postes de travail (cela fera l’objet d’un prochain article ici)
- pour construire certaines images AMI pour notre serveur Jenkins en charge de notre intégration continue
Nous enregistrions déjà très facilement nos images docker privées dans ECR.

Pourquoi est-ce que je vous raconte tout cela ? Eh bien parce que la technologie que nous avons choisie, AWS Fargate, permet d’exécuter des conteneurs sans avoir à gérer des serveurs ou des clusters docker à la main. À partir du moment où vous êtes capable d’empaqueter votre application dans des conteneurs, il devient très facile de les éxécuter dans un réseau privé, d’en créer à la demande et de les arrêter si besoin. Et comme nous allons le voir, c’est à ce moment-là que toutes les planètes se sont alignées pour nous.
Alignement des planètes
Je disais en début de cet article que cette migration avait été indolore pour nous, regardons pourquoi.
- Nous étions prêts : nous pensions déjà à utiliser docker pour répondre à ces problèmes, mais l’utilisation de ECS classique (c’est à dire sans Fargate) restait assez compliqué a priori. Nous avons donc progressé petit à petit dans notre utilisation de docker jusqu’au moment de l’annonce de la sortie de Fargate
- Fargate a été rapidement disponible dans la région Irlande : c’est la région où se situe toute notre production pour le moment : non seulement c’est la moins chère en Europe, mais c’est souvent l’une des premières régions dans le monde à accueillir les nouveautés de AWS ; il faut en général attendre quelques mois pour un déploiement mondial
- Terraform a rapidement mis à jour pour le support de Fargate, mais vraiment rapidement, à un point où nous avons constaté que terraform était en fait prêt avant nous ! Bravo aux équipes chez Hashicorp !
- Nous avions déjà des outils en place pour surveiller l’état des files sous la forme de métriques dans CloudWatch : le script qui met à jour ces métriques était le candidat idéal pour prendre la décision d’ajout de conteneurs quand la taille de la file augmente (scale up)
- Nous utilisons la bibliothèque rq (Redis Queue) pour implémenter notre pattern Producteur/Consommateur. Les workers dans rq ont un mode
bursttrès pratique : le worker s’arrête de travailler (le process unix se termine) quand la file est vide, du coup pas besoin de nous occuper de retirer des workers quand il ne reste plus rien à faire (scale down).
Ainsi notre implémentation a été très simple :
- mise à jour des déclarations des workers sous la forme d’un cluster ECS Fargate avec terraform (et au passage, destruction des serveurs EC2 qui s’occupaient de cette charge) ; il faut bien faire attention au type de tâche Fargate que vous lancez, aux ressources (CPU/mémoire) dont vous avez besoin et au nombre maximum d’instances que vous vous autoriserez
- empaquetage de la partie worker de nos applications dans des conteneurs docker (un simple Dockerfile s’appuyant sur l’image officielle docker pour python)
- mise à jour de notre script de supervision de la taille des files dans redis pour lancer de nouvelles tâches dans Fargate
- mise à jour de nos scripts de release et déploiement qui deviennent un simple tag docker sur ECS et une mise à jour du tag cible pour Fargate.
La configuration avec terraform ressemble à cela :
- déclaration du cluster :
resource "aws_ecs_cluster" "ecs_cluster" {
name = "${var.platform_name}_ecs_cluster"
}
- déclaration d’une tâche :
resource "aws_ecs_task_definition" "my_app_worker" {
family = "${var.platform_name}-my_app_worker"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = "512"
memory = "2048"
execution_role_arn = "arn:aws:iam::aaa:role/ecsTaskExecutionRole"
task_role_arn = "arn:aws:iam::aaa:role/ecs-roles/my_app_worker"
container_definitions = "${local.container_def}"
tags {
Project = "${var.aws_project_name}"
platformName = "${var.platform_name}"
application = "my_app"
}
}
- avec le contenu de la variable
${local.container_def}:
locals {
container_def = <<DEFINITION
[
{
"image": "${var.aws_docker_repository}/my_app_worker:${var.platform_name}",
"name": "worker",
"environment": [
{"name": "DEEPKI_ADDITIONAL_CONFIG_FILES", "value": "xxx"},
{"name": "LC_ALL", "value": "C.UTF-8"}
],
"command": ["--version-check", "my_app-target-version"],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "${var.platform_name}/my_app/worker",
"awslogs-region": "${var.aws_region}",
"awslogs-stream-prefix": "ecs"
}
}
}
]
DEFINITION
C’est très simple, rapide et léger (à comparer avec la création et la maintenance complète d’un serveur traditionnel) comme vous pouvez le constater, nous n’avons même plus besoin de ansible pour ces déploiements, mais une partie du build de notre application embarque désormais des Dockerfiles (qui sont présents dans le même repository git que notre code et non plus dans celui qui nous permet de gérer nos plateformes avec terraform+ansible).
Les difficultés rencontrées
Bien évidement, tout n’a pas été totalement sans anicroche ni sans parfois quelques pertes de fonctionalités : ce qui compte, c’est de pouvoir faire des choix éclairés, d’être capable de justifier ces compromis. Dans notre cas, on y a grandement gagné en confort de déploiement, en solidité de la solution et au final en visibilité de ce qui se déroule sur nos plateformes (même si nous avons dû nous outiller un peu plus pour cela).
- soucis de vocabulaire : au début, nous avions du mal à comprendre le vocabulaire autour de Fargate, en particulier de comprendre la différence entre service et task ; de loin c’est exactement la même chose (des instances docker) mais ça ne porte pas le même nom. Une confusion plus grande nous a frappé car la librairie
rqutilise également le vocable de task pour désigner tout autre chose (une unité de travail à réaliser par un worker) - suivi des coûts : avec des serveurs EC2, il suffit de tagguer les ressources sur les axes de suivi des coûts que l’on désire (par exemple, l’environnement tel que
testouproduction) pour avoir un compte rendu détaillé de nos coûts ; ce n’est pas possible de tagguer les instances Fargate et de suivre sur ces mêmes axes nos divers coûts - suivi en temps réel du nombre d’instances : AWS CloudWatch permet de suivre un grand nombre de métriques en temps réel et dans le temps sur tout ce qui se passe chez eux ; étrangement, c’est impossible de visualiser à ce jour le nombre d’instances de tasks Fargate (suivre le nombre de services que nous n’utilisons pas est possible). Nous nous sommes outillés pour cela avec un script appelé toutes les minutes qui demande à l’API ECS le nombre d’instances en cours et envoie une métrique dans Cloudwatch ; cela nous permet de tracer cette évolution dans le temps :
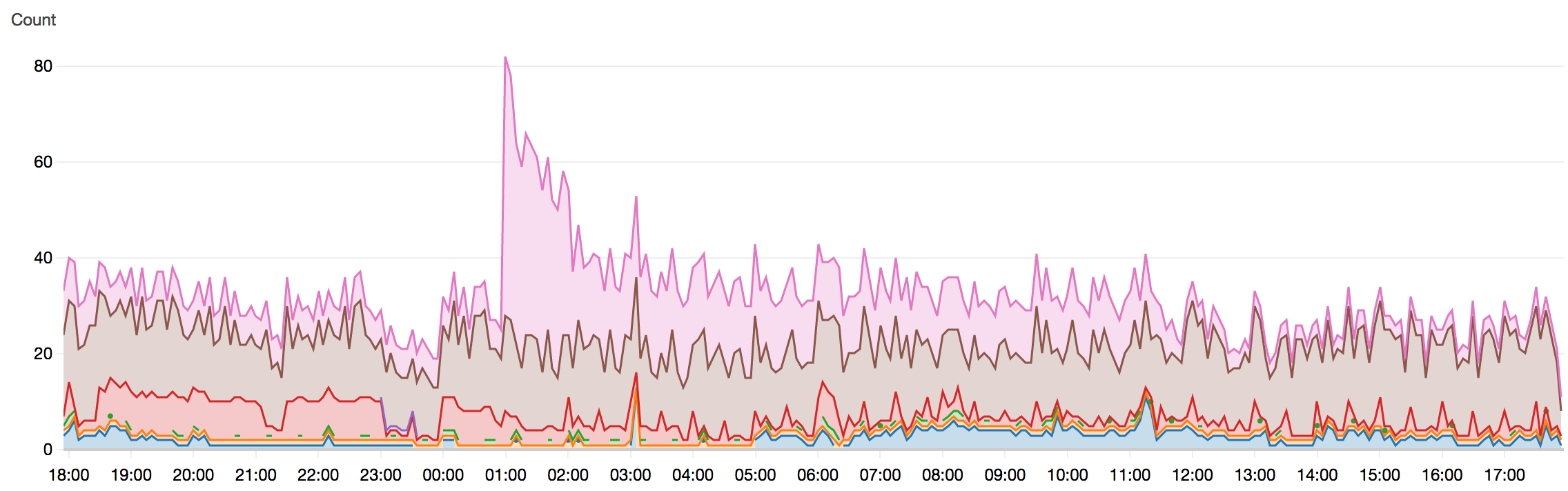
Suivi de nos instances Fargate depuis Cloudwatch grâce à notre script maison
La suite
Ce changement d’architecture était une première étape pour nous, il nous reste donc encore du chemin à parcourir pour toujours rester au top et continuer à rendre un service d’exception à nos utilisateurs :
- Dimensionner plus finement les instances en fonction du travail à réaliser : pour le moment, nous avons dimensionné “par le haut” la taille de nos instances Fargate, mais certaines tâches sont très simples et rapides à réaliser et nécessitent peu de ressources : c’est un peu du gâchis que d’utiliser une instance qui a 16 Go de RAM pour un simple envoi d’email à un utilisateur par exemple.
- Migrer notre dernière application sur ce modèle : notre application visible de nos clients, Deepki Ready, fonctionne encore selon l’ancien mode (avec des serveurs EC2) ; cela nous pose de plus en plus de soucis de dimensionnement dynamique, l’activité des workers de cette application est encore plus variable dans la journée que pour nos autres applications et bien souvent ce sont nos utilisateurs qui attendent que tous les workers aient terminé leurs tâches. Ce qui nous a arrêté pour réaliser le changement est justement la grande variabilité des tâches à réaliser et le dimensionnement de nos instances
- Utiliser Fargate également pour nos frontaux web ? (en mode service) Eh oui, pourquoi continuer à avoir des instances EC2 pour nos applications front ? On pourrait même imaginer un dimensionnement dynamique de ces instances selon notre traffic (il nous faudrait déterminer pour cela la métrique adaptée à notre contexte).
Il nous reste donc encore du travail à accomplir : la maintenance et l’évolution de son architecture est un combat sans fin, de tous les instants. Il est important de s’outiller pour suivre au plus prêt le comportement de ses plateformes, de voir jusqu’où certains choix d’architecture nous rendent service et à partir de quand il faut en changer, s’adapter, évoluer. Il ne faut pas hésiter à remettre en question les choix passés : ils ont été pris dans un contexte différent, les hypothèses sur lesquelles ils s’appuyaient ne sont plus vraies et vous avez probablement appris depuis.
Et vous, comment vous rendez-vous compte que votre architecture a besoin d’être revue ?
Réactions